SceneSmith:
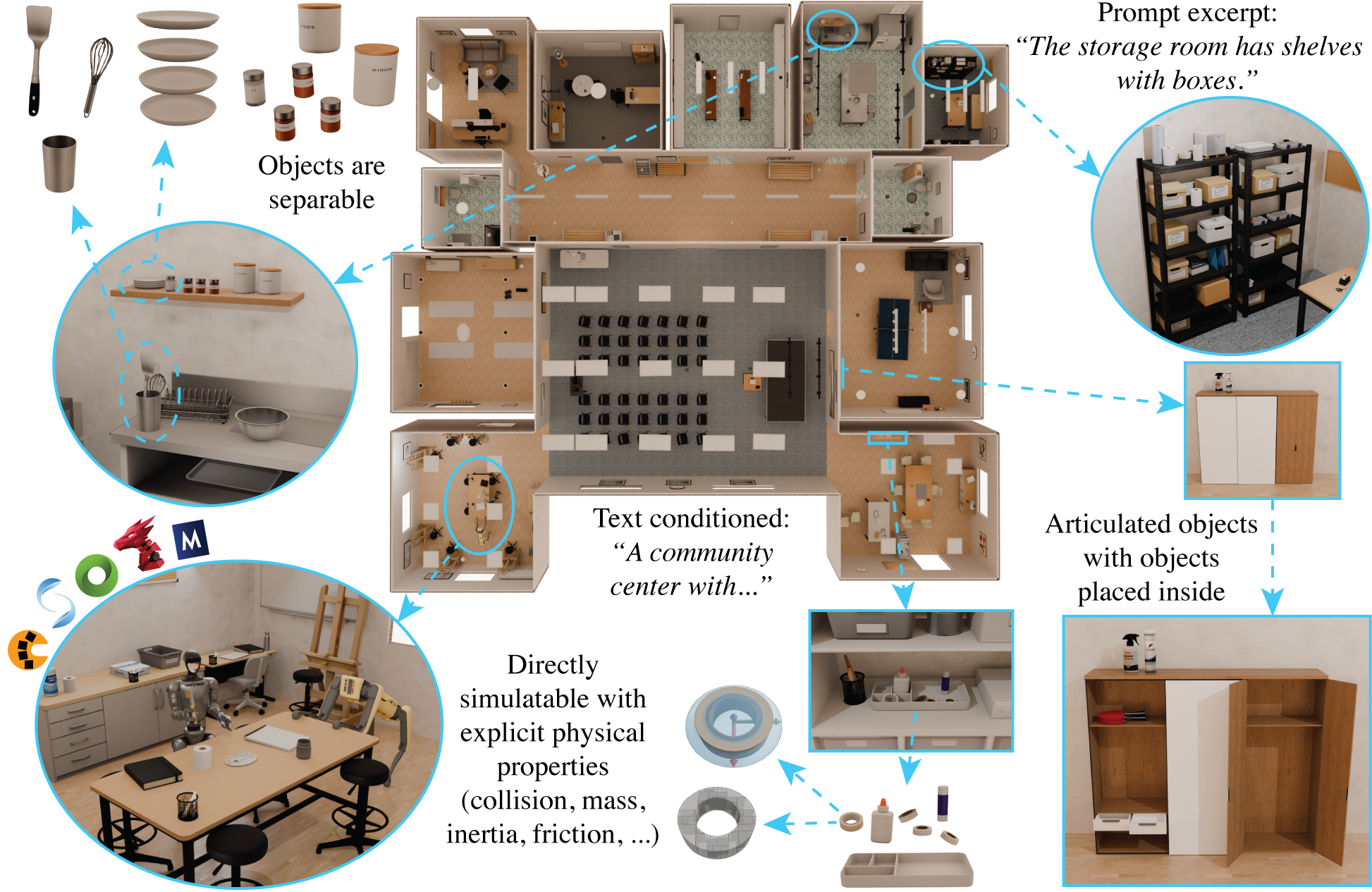
SceneSmith:SceneSmith is a hierarchical agentic framework that generates simulation-ready indoor environments from natural language prompts. VLM agents collaborate across successive stages to construct richly furnished scenes—from single rooms to entire houses. The framework tightly integrates text-to-3D asset generation, articulated object retrieval, and physical property estimation to produce scenes directly usable in physics simulators for robotics research.
“A dining room with a long table set for 12 people…” (hover for full prompt)
“A bookstore with at least 50 books.”
“A cafe with a bar counter, small round tables, and a chalkboard menu…” (hover for full prompt)
“A robotics lab with workbenches, robotic arms, and a 3D printer…” (hover for full prompt)
“A yoga studio with yoga mats, a wall mirror, and meditation cushions…” (hover for full prompt)
“A small family home with a master bedroom, a kids room, a living-dining room, a kitchen, a hallway, and a bathroom…” (hover for full prompt)
SceneSmith constructs scenes through five successive stages, each implemented as an interaction among three VLM agents: a designer that proposes object placements, a critic that evaluates realism and coherence, and an orchestrator that mediates between the two.
SceneSmith scenes are simulation-ready and can be directly used for robotics tasks. Here we demonstrate this by teleoperating a Rainbow RBY1 robot in generated scenes using the Drake simulator.
SceneSmith supports open-vocabulary text input for generating arbitrary indoor scenes, from single rooms to multi-room house-scale environments. The object vocabulary is also unbounded, as SceneSmith leverages text-to-3D generation to create any object on demand.
All furniture and manipulands in SceneSmith-generated scenes are fully movable in simulation. The video above demonstrates this by applying earthquake-style shaking to entire scenes, showing that every placed object responds to physical forces.
Select a scene to explore. Click objects to view them in isolation.
Scenes shown are slightly lower quality than originals due to compression, mesh decimation, and texture downsampling for faster web loading.
Loading scene...
Click an object in the scene to select it
Multi-room environments with complex layouts. Select a scene to explore.
House scenes are larger and may take longer to load.
Loading scene...
Click an object in the scene to select it
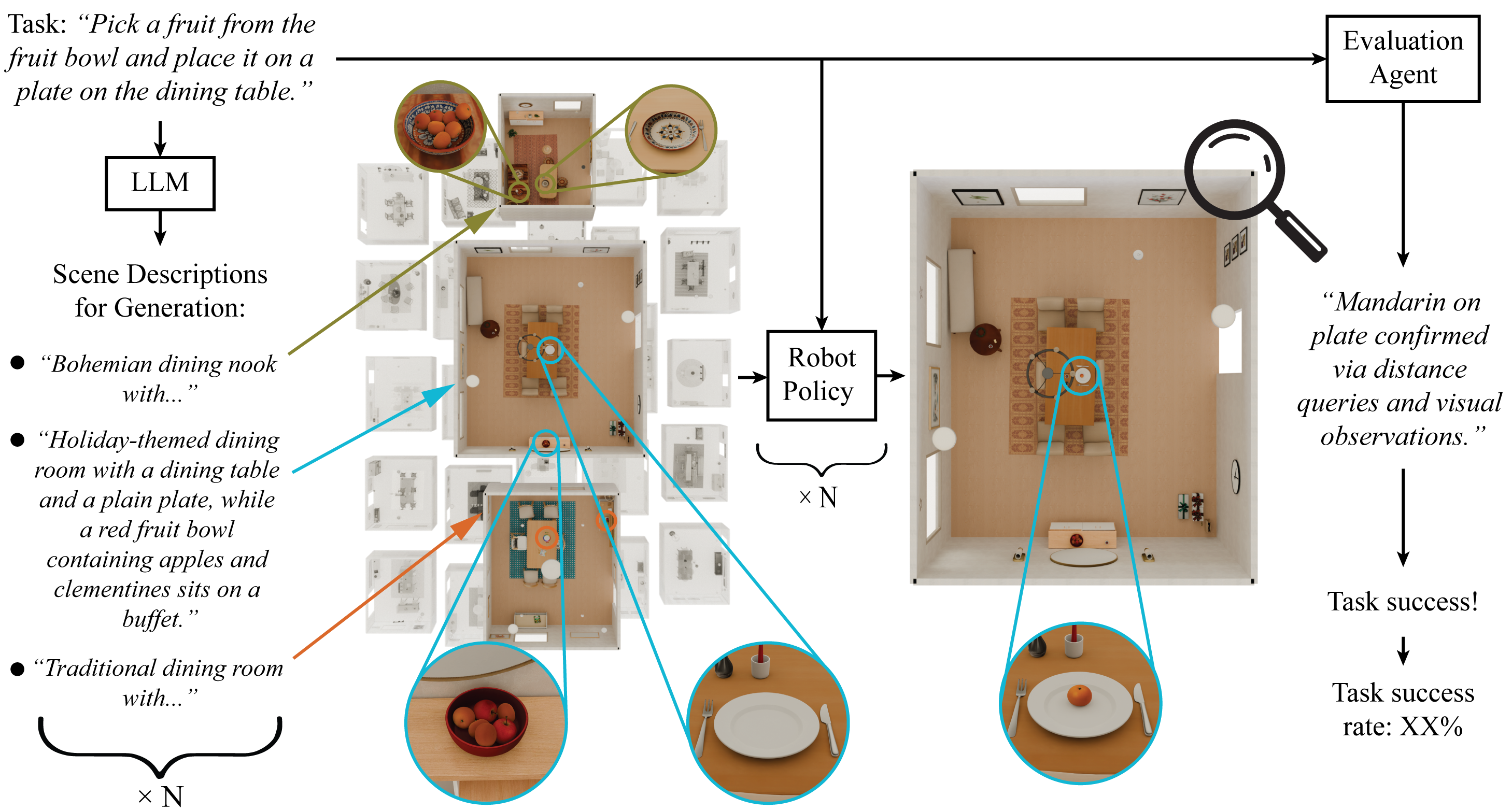
Robot manipulation evaluation pipeline. Given a manipulation task (e.g., “Pick a fruit from the fruit bowl and place it on a plate”), an LLM generates diverse scene prompts specifying scene constraints implied by the task. SceneSmith generates scenes from each prompt. A robot policy attempts the task in simulation, and an evaluation agent verifies success using simulator state queries and visual observations. This enables scalable policy evaluation without manual environment or success predicate design.
“Pick a coke can from the shelf and place it on the table”
“Bring the water bottle from the kitchen and place it on the coffee table in the living room”
“Pick a cup from the floor and place it in the sink”
“Pick a fruit from the fruit bowl and place it on a plate on the dining table”
“Pick a coke can from the shelf and place it on the table”
“Bring the water bottle from the kitchen and place it on the coffee table in the living room”
“Pick a cup from the floor and place it in the sink”
“Pick a fruit from the fruit bowl and place it on a plate on the dining table”
“Pick a coke can from the shelf and place it on the table”
“Pick a fruit from the fruit bowl and place it on a plate on the dining table”
“Pick a coke can from the shelf and place it on the table”
The videos above show rollouts of a model-based pick-and-place policy executing across SceneSmith-generated scenes. For each task, an LLM produces diverse scene prompts and SceneSmith generates 25 unique environments, yielding 100 evaluation scenes spanning four manipulation tasks. A vision-language model parses each task into structured goal components, and the policy plans collision-free motions via RRT-Connect. These rollouts serve as inputs to our automatic evaluation system: an agentic evaluator that verifies task success through simulator state queries and visual observations—without hand-crafted success predicates. The evaluator achieves 99.7% agreement with human labels, confirming that SceneSmith-generated scenes enable scalable, fully automatic policy evaluation.
Nicholas Pfaff1,
Thomas Cohn1,
Sergey Zakharov2,
Rick Cory2,
Russ Tedrake1
1Massachusetts Institute of Technology,
2Toyota Research Institute
@misc{scenesmith2026,
title={SceneSmith: Agentic Generation of Simulation-Ready Indoor Scenes},
author={Nicholas Pfaff and Thomas Cohn and Sergey Zakharov and Rick Cory and Russ Tedrake},
year={2026},
eprint={2602.09153},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2602.09153},
}This work was partially supported by Amazon.com (PO No. 2D-19158853), the Office of Naval Research (ONR) under Grant No. N00014-22-1-2121, the Toyota Research Institute (TRI), and the National Science Foundation Graduate Research Fellowship Program under Grant No. 2141064. This article reflects only the views of the authors and not those of TRI or any other Toyota entity. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation or other funding organizations.
We thank Hongkai Dai, Jeremy Binagia, Peter Werner, and Tom Erez for helpful discussions. We also thank Patrick Farrell for assistance with the videos.